1 Randomization inference is a method for calculating p-values for hypothesis tests
One of the advantages of conducting a randomized trial is that the researcher knows the precise procedure by which the units were allocated to treatment and control. Randomization inference considers what would have happened under all possible random assignments, not just the one that happened to be selected for the experiment at hand. Against the backdrop of all possible random assignments, is the actual experimental result unusual? How unusual is it?
2 Randomization inference starts with a null hypothesis
After we have conducted an experiment, we observe outcomes for the control group in their untreated state and outcomes for the treatment group in their treated state.5 In order to simulate all possible random assignments, we need to stipulate the counterfactual outcomes – what we would have observed among control units had they been treated or among treated units had they not been treated. The sharp null hypothesis of no treatment effect for any unit is a skeptical worldview that allows us to stipulate all of the counterfactual outcomes. If there were no treatment effect for any unit, then all the control units’ outcomes would have been unchanged had they been placed in treatment. Similarly, the treatment units’ outcomes would have been unchanged had they been placed in the control group. Under the sharp null hypothesis, we therefore have a complete mapping from our data to the outcomes of all possible experiments. All we need to do is construct all possible random assignments and, for each one, calculate the test statistic (e.g., the difference in means between the assigned treatment group and the assigned control group). The collection of these test statistics over all possible random assignments creates a reference distribution under the null hypothesis. If we want to know how unusual our actual experimental test statistic is, we compare it to the reference distribution. For example, our experiment might obtain an estimate of 6.5, but 24% of all random assignments produce an estimate of 6.5 or more even in the absence of any treatment effect. In that case, our one-tailed p-value would be 0.24.6
Code
# Worked example of randomization inferencelibrary(ri2) # load the RI2 packagelibrary(coin) # load the coin packageset.seed(1234567) # random number seed, so that results are reproducible# Data are from Table 2-1, Gerber and Green (2012)dat <-data.frame(Y0 =c(10, 15, 20, 20, 10, 15, 15),Y1 =c(15, 15, 30, 15, 20, 15, 30),Z =c(1,0,0,0,0,0,1)) # one possible treatment assignmentdat$Y <-with(dat,Y1*Z + Y0*(1-Z)) # observed outcomes given assignment# Represent the design with 2 units assigned to treatment and 5 to controldeclaration <-declare_ra(N =7, m =2)print(declaration)
Random assignment procedure: Complete random assignment
Number of units: 7
Number of treatment arms: 2
The possible treatment categories are 0 and 1.
The number of possible random assignments is 21.
The probabilities of assignment are constant across units:
prob_0 prob_1
0.7142857 0.2857143
Code
# Notice that there are 21 ways to assign 2 treatments to 7 total units# the first way is to assign treatments to units 1 and 2, and the second to units 1 and 3, etc.combn(7,2)
# Conduct Randomization Inference# using a difference in means test statistic by defaultri2_out <-conduct_ri(formula = Y ~ Z,declaration = declaration,sharp_hypothesis =0,data = dat)summary(ri2_out)
term estimate two_tailed_p_value
1 Z 6.5 0.3809524
Code
# The ingredients:# An observed test statisticobs_mean_diff <-with(dat,mean(Y[Z==1])-mean(Y[Z==0]))# The distribution of the test statistic under the null:table(ri2_out$sims_df$est_sim)
# Another approach using permutations rather than an exact approach using the coin package# And using a standardized difference of means (like a t-test) rather than the raw# difference in means used abovedat$ZF <-factor(1-dat$Z) # oneway_test wants treatment to be a factort_test_exact <-oneway_test(Y~ZF,data=dat,distribution=exact())print(t_test_exact)
Exact Two-Sample Fisher-Pitman Permutation Test
data: Y by ZF (0, 1)
Z = 1.2211, p-value = 0.381
alternative hypothesis: true mu is not equal to 0
Code
pvalue(t_test_exact)
[1] 0.3809524
Code
## the standardized difference in meansstatistic(t_test_exact)
[1] 1.221137
Code
# The equivalent of the table showing the distribution above# only here using standardized test statisticsrbind(support(t_test_exact),# The probabilities of each possible test statistic value under the null.dperm(t_test_exact,x=support(t_test_exact))*21)
# Compare results to traditional t-test with unequal variance# notice that the results are not the same because the t.test is assuming a# t-distribution for the null distribution of the test statistic.t.test(Y~Z,data=dat,alternative ="less",mu =0, var.equal =FALSE)
Welch Two Sample t-test
data: Y by Z
t = -0.8409, df = 1.1272, p-value = 0.2708
alternative hypothesis: true difference in means between group 0 and group 1 is less than 0
95 percent confidence interval:
-Inf 33.94232
sample estimates:
mean in group 0 mean in group 1
16.0 22.5
Welch Two Sample t-test
data: Y by Z
t = -0.8409, df = 1.1272, p-value = 0.5416
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-82.03199 69.03199
sample estimates:
mean in group 0 mean in group 1
16.0 22.5
3 Randomization inference gives exact p-values when all possible random assignments can be simulated
When the reference distribution is known based on a complete census of possible random assignments, p-value calculations are exact – there are no theoretical approximations based on assumptions about the shape of the sampling distribution. Sometimes the set of possible random assignments is so large that a full census is infeasible. In that case, the reference distribution can be approximated to an arbitrary level of precision by randomly sampling from the set of possible random assignments a large number of times. Thousands or tens of thousands of simulated random assignments are recommended.
4 Randomization inference requires the analyst to specify a test statistic and some are more informative than others
In principle, any test statistic can be used as input for randomization inference, which in turn outputs a p-value. Some test statistics provide more informative results than others, however. For example, although the simple difference-in-means often performs well, there are good arguments for other test statistics, such as the t-ratio using a robust standard error.7 In this case, the researcher would calculate the test statistic for the actual experiment and compare it to a reference distribution of robust t-statistics under the sharp null hypothesis of no effect.
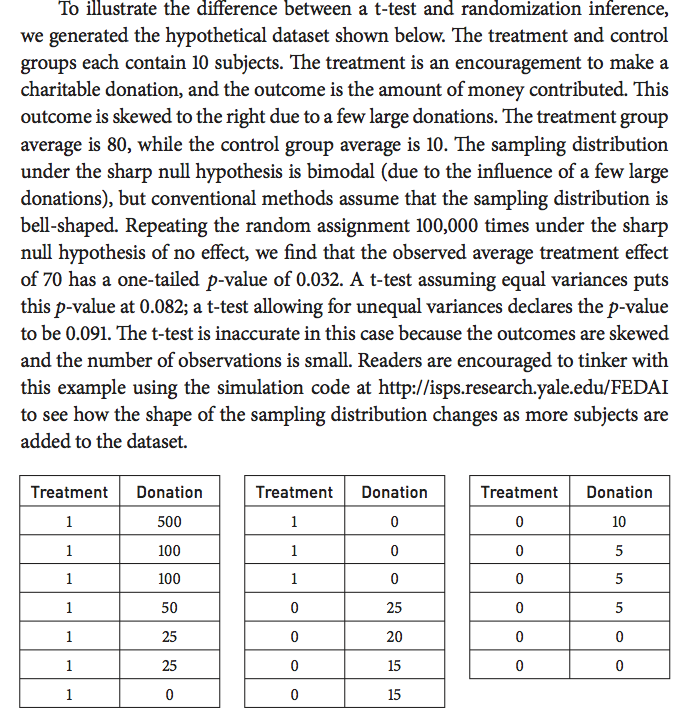
5 Randomization inference may give different p-values from conventional tests when the number of observations is small and when the distribution of outcomes is non-normal
Conventional p-values typically rely on approximations that presuppose either that the outcomes are normally distributed or that the subject pool is large enough that the test statistics follow a posited sampling distribution. When outcomes are highly skewed, as in the case of donations (a few people donate large sums, but the overwhelming majority donate nothing), conventional methods may produce inaccurate p-values. Gerber and Green (2012) (p.65) give the following example in which randomization inference and conventional test statistics produce different results:
6 Randomization inference is useful for clustered designs: clustering, fuzzy clustering
Cluster random assignment is notorious for throwing off inference, especially when the number of clusters is small. (See our guide 10 Things to Know About Cluster Randomization for more details.) Robust cluster standard errors tend to be downwardly biased when there are fewer than a dozen clusters, and bias is evident in simulations even when the number of clusters rises above thirty. Randomization inference sidesteps the problem of faulty t-ratios based on robust cluster standard errors. Instead, the reference distribution is calculated based on the set of possible clustered assignments, which takes account of the sampling variability associated with clustered assignment.
Randomization inference is even more valuable when the clustered standard errors are difficult or impossible to compute. This situation arises in the context of “fuzzy clustering” – instances in which sets of observations have correlated assignments, but the correlation is less than perfect. Fuzzy clustering, for example, occurs in place-based random assignments in which treatment effects spill over to nearby units (e.g., anti-crime interventions that may displace crime to nearby areas). By simulating outcomes under alternative random assignments, randomization inference allows the researcher to readily gauge the p-values of test statistics under the null hypothesis of no treatment and no spillover effects (i.e., if the police intervention were ineffective and neither deterred crime nor pushed it around the corner).
7 Randomization inference is valuable when randomization procedures are complicated
Sometimes the implementation of random assignment hinges on contingencies that are difficult to model statistically. A common case occurs when researchers test for covariate balance after conducting a random assignment and then redo the randomization if a balance test reveals significant covariate imbalance. Characterizing the sampling distribution of this procedure is challenging, especially if the treatment and control groups contain different numbers of subjects. Fortunately, randomization inference easily generates a reference distribution by simulating admissible random assignments (i.e., those that would have passed the balance test). The same goes for complicated blocking or adaptive designs.
8 Randomization inference can be used to address issues of multiple comparisons8
Randomized trials that involve multiple outcomes, multiple treatments, or multiple subgroup comparisons raise concerns that splashy results may pop up by chance even if there were no treatment effects. (See our guide 10 Things to Know About Multiple Comparisons for more details on this problem.) Randomization inference helps facilitate the evaluation of hypotheses of the form: under the null hypothesis of no treatment effect, what is the probability that at least three outcomes show nominal p-values of less than 0.05? For each random assignment under the sharp null of no treatment effect, calculate the number of apparent p < 0.05 coefficients in order to form the reference distribution. A similar approach may be applied to other targets of inference, such as the p-value of observing two significant treatment-by-covariate interactions or observing four significant treatment arms.
9 Randomization inference cannot be applied without additional assumptions to inferences about quantities such as complier average causal effects
Randomization inference is a flexible method that can accommodate null hypotheses other than the sharp null of no effect for any unit. The methods described above could also be applied to the null hypothesis that all units have a treatment effect of seven.
On the other hand, randomization inference cannot be applied with additional assumptions in cases where hypotheses focus on unobserved subgroups, such as compliers in cases of non-compliance with the treatment. We cannot simulate the sampling distribution of the estimated complier average causal effect when we lack knowledge of who the compliers are. (In the case of one-sided noncompliance, we know who the compliers are in the treatment group but not the control group.) In this case, the researcher may have to be content using randomization inference to assess the sharp null hypothesis that the intention-to-treat effect is zero.9
10 In some applications, randomization inference may not be worth the trouble
Old-fashioned approximate methods work well when the assumptions on which the approximations rest are sound. For example, when an experiment involves random assignment of individual subjects, outcomes are distributed more or less symmetrically around the mean, and the number of subjects is greater than 100, the difference between conventional p-values and RI p-values may be negligible. Randomization inference may still be useful as the final word, but it rarely changes inferences substantively under these circumstances. The method is valuable primarily for nonstandard applications in which outcomes are skewed, subject pools are small, or the method of assignment is complex.
Note on available software for implementing randomization inference. For the latest R package for randomization inference, see here. For randomization inference code specifically tailored to the special features of binary outcomes, see here. Stata users may find an all-purpose package here.
Chung, EunYi, and Joseph P. Romano. 2013. “Exact and Asymptotically Robust Permutation Tests.”The Annals of Statistics 41 (2): 484–507.
Gerber, Alan S., and Donald P. Green. 2012. Field Experiments: Design, Analysis, and Interpretation. New York: W.W. Norton.
Small, Dylan S., Thomas R. Ten Have, and Paul R. Rosenbaum. 2008. “Randomization Inference in a Group–Randomized Trial of Treatments for Depression: Covariate Adjustment, Noncompliance, and Quantile Effects.”Journal of the American Statistical Association 103 (481): 271–79.
Footnotes
Originating author: Don Green. Thanks to Winston Lin and Gareth Nellis, who commented on an earlier draft. Revisions: Jake Bowers, 8 July 2025. The guide is a live document and subject to updating by EGAP members at any time.↩︎
Originating author: Don Green. Thanks to Winston Lin and Gareth Nellis, who commented on an earlier draft. Revisions: Jake Bowers, 8 July 2025. The guide is a live document and subject to updating by EGAP members at any time.↩︎
Originating author: Don Green. Thanks to Winston Lin and Gareth Nellis, who commented on an earlier draft. Revisions: Jake Bowers, 8 July 2025. The guide is a live document and subject to updating by EGAP members at any time.↩︎
We focus here on randomization inference as applied to hypothesis testing. Randomization inference may also be used for construction of confidence intervals, but this application requires stronger assumptions. See Gerber and Green (2012), chapter 3.↩︎
As explained in other guides, the fundamental problem of causal inference is that we cannot observe what would have happened to those in control group had they be treated, nor can we observe what would have happened to those in the treatment group had they not been treated.↩︎
One-tailed tests consider the null hypothesis of no effect against an alternative hypothesis that the average treatment effect is positive (negative). Two-tailed tests evaluate a null hypothesis against the alternative that the ATE is nonzero, whether positive or negative. In that case, the p-value may be assessed by calculating the proportion of simulated random assignments that are at least as large as the observed test statistic in absolute value.↩︎
See Chung and Romano (2013). This “studentized” approach makes sense when there is reason to believe that the treatment changes the variance in outcomes in an experiment with different numbers of subjects in treatment and control.↩︎