When variables are missing some data values, we say that there is “missing data.” Depending on your software and the coding of the dataset, missing values may be coded as NA, ., an empty cell (""), or a common numeric code (often -99 or 99).
The consequences of missing data for estimation and interpretation depend on the type of variable missing the data. For our purposes, we will consider three types of variables: pretreatment covariates, treatment indicator(s), and outcome (or dependent) variables. Pretreatment covariates, often known simply as “covariates,” are variables that we observe and measure before treatment is assigned. Outcome (or dependent) variables refer to outcomes that are measured after the assignment of treatment.
Missing data emerges for different reasons. In survey data, a respondent could decline to answer a question or quit the survey without completing all questions. In a panel survey, some subjects may skip the second or later waves. With administrative data, records may be lost at some point in the process of collecting or recording data. To the extent that we can know the process by which data becomes missing, we can better understand the consequences of missing data for our analysis and inferences.
2 2. Missing treatment or outcome data can bias our ability to describe empirical patterns and estimate causal effects.
Missing data can induce bias in our estimates of descriptive patterns and causal effects. Consider a researcher trying to describe the income distribution in a country with survey data. Some individuals’ incomes are missing but the researcher describes the non-missing data at hand. Suppose low-income individuals are less likely to report their income than high-income individuals, thus missingness concentrates in the lower portion of the distribution. Then, the researcher’s characterization of the income distribution is apt to be biased. For example, the researcher’s estimate of median income is bound to be higher than the true (unknown) median income because more data is missing from the lower portion of the distribution. Since missingness is correlated with the variable that we are trying to describe, our characterization of the median of the distribution is biased.
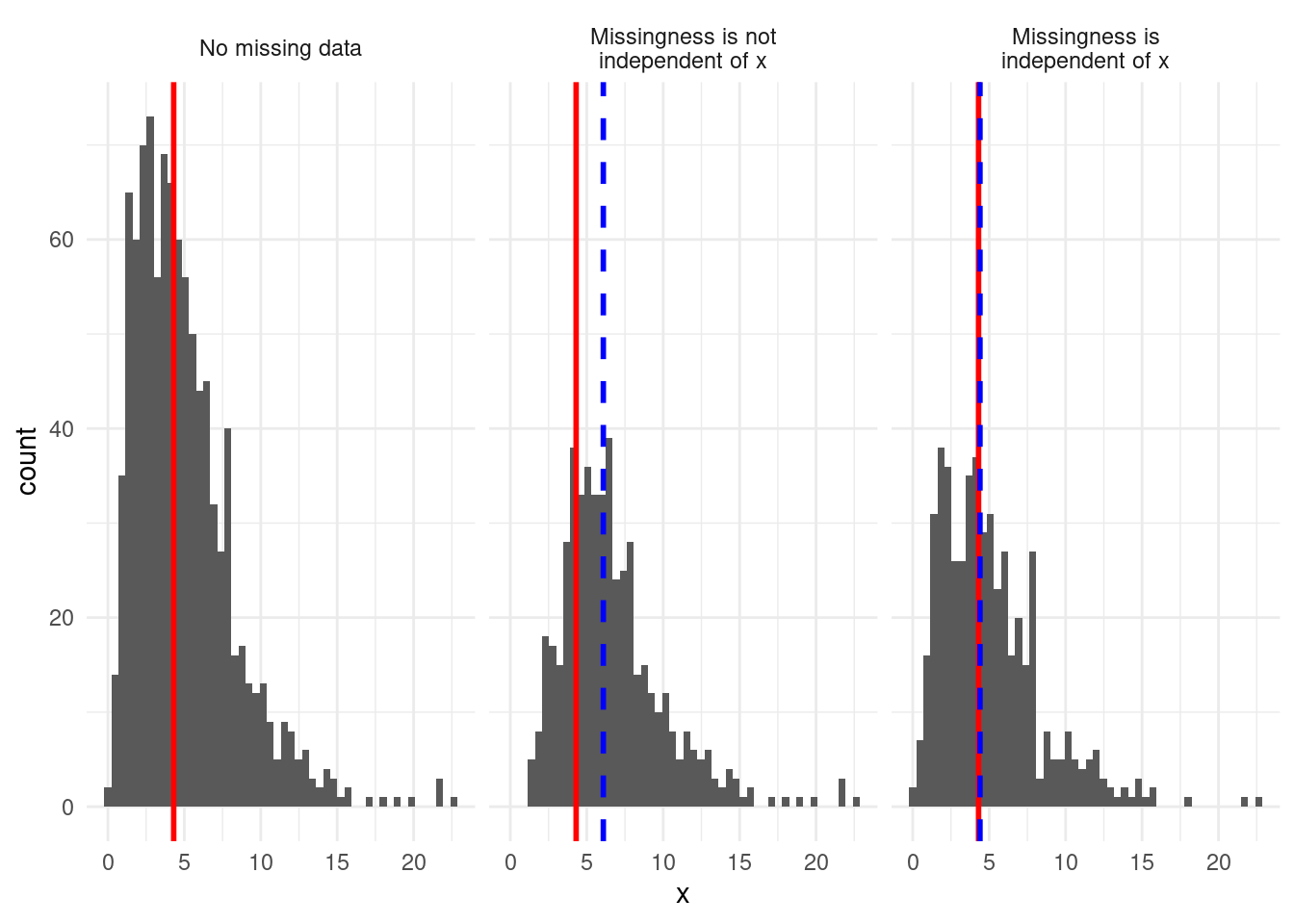
We can illustrate two types of missingness by considering a variable \(x\) – for example, income, as above. The left panel shows the full distribution of the variable \(x\) without missing data. The middle panel depicts a scenario in which simulated missingness in \(x\) is not independent of \(x\) – low values of \(x\) are much more likely to be missing. The right panel depicts a scenario in which simulated missingness in \(x\) is independent of \(x\) (often called “missing at random”). The red line represents the median of the distribution without missingness. The blue lines represent the median of the observed data in each simulation. Where missingness is not independent of \(x\), we observe that the median of the nonmissing data is, in this instance, higher than the true median. This illustrates that missing data can bias our descriptions of single variables.
Similarly, when we seek to estimate causal effects, some patterns of missing data can lead to biased estimates of causal effects. In particular, missingness of the treatment indicator or the outcome variable of interest can induce bias in estimates of the ATE. First, consider missingness of an outcome variable \(Y_i(Z)\). Adopting some notation from Gerber and Green (2012), define “reporting” as a potential outcome of a treatment, \(Z\), as \(R_i(Z) \in \{0, 1\}\). In this notation, \(R_i(Z) = 0\) indicates that \(Y_i(Z)\) is missing and \(R_i(Z)=1\) indicates that the outcome is non-missing. Using this notation, we can express the ATE as:
\[\begin{align}
\underbrace{E[Y_i(1)]-E[Y_i(0)]}_{ATE} =& \underbrace{E[R_i(1)]E[Y_i(1)|R_i(1) = 1]}_{Z = 1\text{ and }Y_i \text{ is not missing}} + \underbrace{(1-E[R_i(1)])(E[Y_i(1)|R_i(1) = 0])}_{Z = 1 \text{ and } Y_i \text{ is missing}} - \\
&\underbrace{E[R_i(0)]E[Y_i(0)|R_i(0) = 1]}_{Z = 0 \text { and } Y_i \text{ is not missing }} - \underbrace{(1-E[R_i(0)])E[Y_i(0)|R_i(0) = 0]}_{Z = 0 \text { and } Y_i \text{ is missing }}
\end{align}\]
If we condition our analysis on on non-missing outcomes, our estimator of the ATE is:
\[E[Y_i(1)|R_i(1)=1] - E[Y_i(0) |R_i(0)=1]\]
Examining the preceding equations, the estimator using only only the non-missing outcomes is only (necessarily) equivalent to the ATE if:
There is no missingness, \(E[R_i(1)] = 1\) and \(E[R_i(0)] = 1\).
Missingness is independent of potential outcomes:
\[
\begin{align}
\underbrace{E[Y_i(1)|R_i(1) = 1]}_{E[Y_i(1)] \text{ if } Y_i(1) \text{ is not missing }} &= \underbrace{E[Y_i(1)|R_i(1) = 0]}_{E[Y_i(1)] \text{ if } Y_i(1) \text{ is missing }}\\
&\text{and } \\
\underbrace{E[Y_i(0)|R_i(0) = 1]}_{E[Y_i(0)] \text{ if } Y_i(0) \text{ is not missing }} &= \underbrace{E[Y_i(0)|R_i(0) = 0]}_{E[Y_i(0)] \text{ if } Y_i(0) \text{ is missing }}
\end{align}
\]
Otherwise, the analysis conditional upon observing \(Y_i(Z)\) can induce an unknowable (but boundable) amount of bias in our estimate of the ATE.
We often do not think of missingness of the treatment indicator in experiments. Indeed, competent administration of an experiment generally ensures against missing treatment values. Nevertheless, it is important to note that missingness of the treatment indicator can also produce bias if missingness is not independent of potential outcomes.
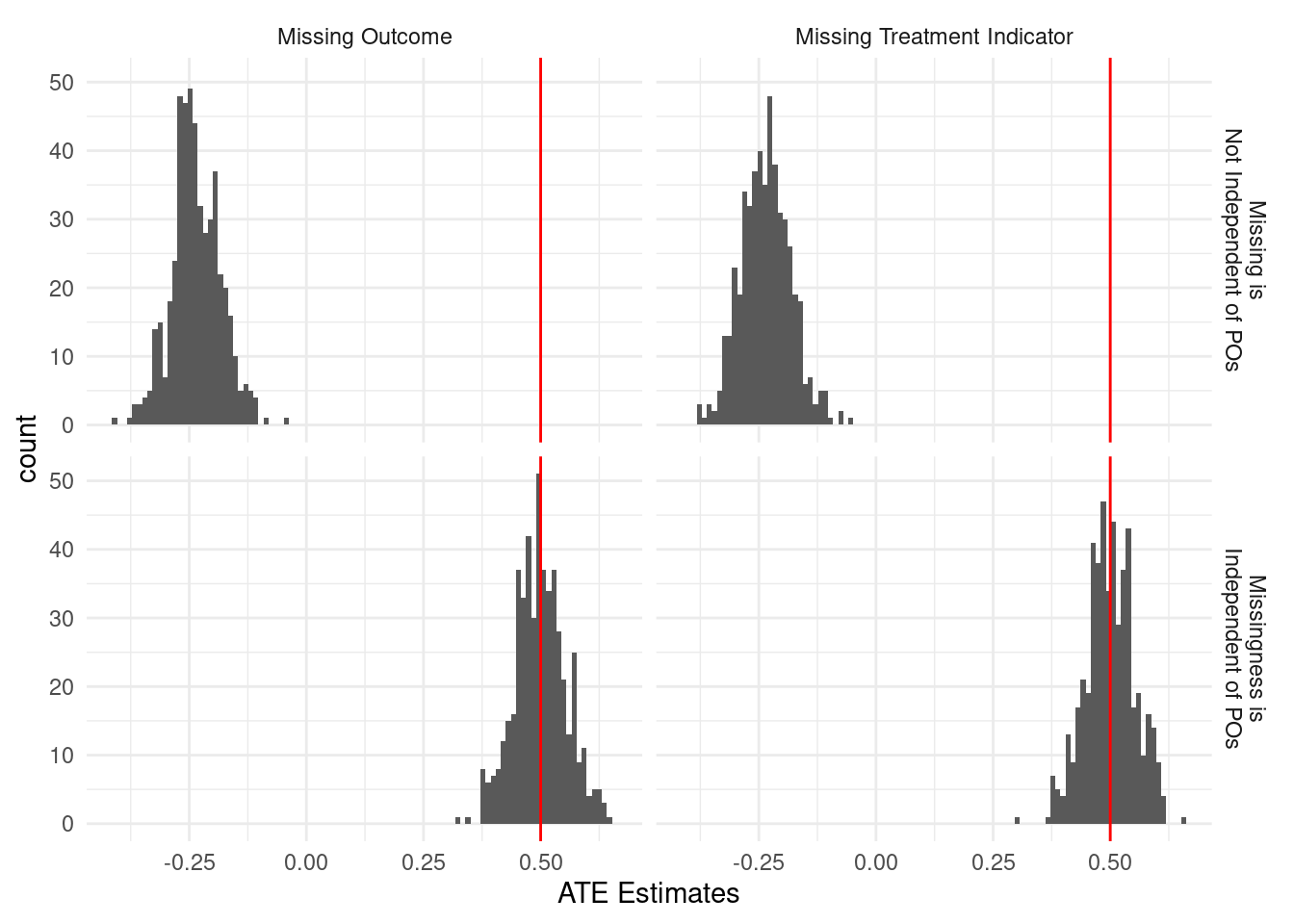
The following simulation shows the consequences of two types of missingness for estimation of the ATE. We set the true ATE to 0.5 (the red vertical lines) in all cases. We simulate missingness through two types of data generating processes. In both cases, all missingness occurs among subjects in treatment (\(Z = 1\)). In the top panel, missingness is most likely among subjects in treatment with higher values of the outcome \(Y_i(1)\). In the bottom pannel, missingness is independent of the value of \(Y_i(1)\). If missingness is correlated with potential outcomes, the estimator of the ATE is biased (top row). This occurs whether we are missing values of the outcome (left column) or the treatment indicator (right column). In contrast, when missing data is independent of potential outcomes, the estimator is unbiased (bottom row).
3 3. The potential for bias increases in the proportion of treatment or outcome data that is missing.
Returning to the equations in #2, it is useful to identify the terms that we can estimate (know) as analysts of a dataset. Rewriting the expression for the ATE in the presence of missing data, we can estimate:
The proportion of missingness in treatment and control: \(\color{red}{E[R_i(1)]}\) and \(\color{red}{E[R_i(0)]}\).
The expectation of the outcome variable among reporters (non-missing data) in treatment and control: \(\color{red}{E[Y_i(1)|R_i(1) = 1]}\) and \(\color{red}{E[Y_i(0)|R_i(0)=1]}\)
These expressions are colored in the following equation.
\[\begin{align}
\underbrace{E[Y_i(1)]-E[Y_i(0)]}_{ATE} =& \underbrace{\color{red}{E[R_i(1)]E[Y_i(1)|R_i(1) = 1]}}_{Z = 1\text{ and }Y_i \text{ is not missing}} + \underbrace{(1-E[R_i(1)])(E[Y_i(1)|R_i(1) = 0])}_{Z = 1 \text{ and } Y_i \text{ is missing}} - \\
&\underbrace{\color{red}{E[R_i(0)]E[Y_i(0)|R_i(0) = 1]}}_{Z = 0 \text { and } Y_i \text{ is not missing }} - \underbrace{(1-E[R_i(0)])E[Y_i(0)|R_i(0) = 0]}_{Z = 0 \text { and } Y_i \text{ is missing }}
\end{align}\]
We are ultimately interested in estimating the ATE, \(E[Y_i(1)]-E[Y_i(0)]\). One straightforward implication of this expression is that the magnitude of bias possible for an estimator of the ATE on non-missing observations increases in the amount of missingness. As \(E[R_i(1)] \rightarrow 1\) and \(E[R_i(0)]\rightarrow 1\), bias stemming from missing outcome data converges to 0. In contrast, when we are missing a large proportion of the data, the magnitude of possible bias increases. Thus, our concerns about missing data should increase as the amount (proportion) of missingness increases.
4 4. The consequences of missing data for bias in estimates of causal effects depend on the type of variable that is missing.
Missingness of pretreatment covariates need not induce bias in our estimates of the ATE. However, researchers can actually induce bias through improper treatment of missing pretreatment covariate data. If treatment is randomly assigned, treatment assignment should be orthogonal to pre-treatment missingness. In other words, pre-treatment missingness should be balanced across treatment assignment conditions.
However, we should avoid “dropping” (excluding) observations based on pretreatment missingness for two reasons. First, it is possible to induce bias in our estimate of an ATE by dropping observations with pre-treatment missingness. After dropping these observations, we can estimate an unbiased estimate the local average treatment effect (LATE) among observations with no missing pretreatment data. However, if treatment effects vary with missingness of pretreatment variables, this LATE may be quite different than the ATE. Second, as we drop observations the number of observations decreases, reducing our power to detect a given ATE. In sum, we should refrain from dropping observations based on pre-treatment covariates to avoid inducing bias or efficiency loss in our estimates of the ATE.
In contrast, missingness of the treatment indicator or outcome variable(s) can induce bias in our estimates of causal effects, as demonstrated in #2. This categorization informs the strategies that we adopt to address the consequences of missing data.
5 5. What assumptions do we invoke when we “ignore” treatment or outcome missingness in estimation?
Suppose that we analyze a dataset with missing treatment or outcome data while ignoring the missingness. If we “ignore” the missingness, we drop observations for which we lack a value for one of these variables. If we proceed to estimate the ATE on the subsample of data for which we have full data for both treatment and outcomes, we estimate:
\[E[Y_i(1)|R_i(1)]- E[Y_i(0)|R_i(1)]\]
This is necessarily equivalent to the ATE estimand \(E[Y_i(1)]-E[Y_i(0)]\) if missingness is independent of potential outcomes (MIPO), i.e. \(Y_i(Z) \perp R_i(Z)\)(Gerber and Green 2012). Thus, to interpret \(E[Y_i(1)|R_i(1)]- E[Y_i(0)|R_i(1)]\) as an unbiased estimator of the ATE, we must impose an assumption that MIPO.
The assumption that MIPO is most plausible when missingness occurs by some random process. Under what conditions might this assumption be plausible? Perhaps we were only able to gather a random subset of administrative outcome data. In this case, missingness would be independent of both potential outcomes and pretreatment covariates. Alternatively, idiosyncratic behavior in data collection (enumerator absence or error) that is plausibly unrelated to potential outcomes may also be consistent with MIPO. On the other hand, survey non-response or other forms of outcome measurement dependent on subject reporting are often much harder to justify under MIPO. Because we cannot validate MIPO, we depend on researchers’ consideration of whether the assumption is plausible under a given data generating process. Where MIPO is not plausible, we should not simply “ignore” missing data in estimation. In these cases, researchers should consider the methods described in #6-#10.
6 6. Why should we assess whether missingness of outcomes is related to treatment assignment?
When researchers encounter missingness in an experiment, they often examine the relationship between missingness of outcomes and treatment assignment. We have denoted reporting (or non-missingness) as a potential outcome of treament assignment, \(R_i(Z)\). For a binary treatment, we can denote four “types” of subjects in the experiment, as denoted in the following table.
Type
Proportion
\(R_i(1)\)
\(R_i(0)\)
Always Reporter
\(\pi_A\)
1
1
If Treated Reporter
\(\pi_T\)
1
0
If Untreated Reporter
\(\pi_U\)
0
1
Never Reporter
\(\pi_N\)
0
0
In the case in which missingness is related to potential outcomes but not to treatment assignment, we are generally not able to identify an unbiased estimate of the ATE. However, we may be interested in identifying the LATE among always reporters – those subjects for which we observe the outcome regardless of treatment assignment. This effect can be a main estimand of interest and even the most policy-relevant estimand in certain settings. However, to estimate this LATE, we want to be sure that the outcomes that we observe are those of always reporters, not if-treated or if-untreated reporters.
To assess the plausibility of ths conjecture, we often examine the relationship between treatment assignment and reporting (non-missingness). Using the notation from the table, we can estimate:
If we find no difference in reporting across treatment groups, this test provides no evidence that \(\pi_T \neq \pi_U\). However, to further justify that the complete observations in the data are those of “always reporters,” we further must know that \(\pi_T = \pi_U = 0\). We cannot test this by examining the relationship between reporting and treatment assignment. As such, we generally complement this test with a justification of why reporting should not be endogenous to treatment assignment: for example by assessing covariate balance between treated and control units who are not missing, or by assessing covariate balance between units with missing vs non-missing outcomes. If reporting is not endogenous, then in principle the assumption that \(\pi_T = \pi_U = 0\) holds. As such, if we find no evidence of differential levels of reporting and see no way that reporting should be endogenous to treatment, we can justify that the \(E[Y_i(1)|R_i(1) = 1] - E[Y_i(0)|R_i(0) = 1]\) estimates the LATE among always reporters.
7 7. What is imputation?
The most common approaches used to deal with missing data involve the imputation or “filling in” of missing values. In the following dataset with missingness, imputation procedures “fill in” the missing data – the NAs.
Xobs
Z
Yobs
-1.2070
0
3
NA
0
2
1.0840
1
3
-2.3460
1
4
0.4291
1
2
0.5061
0
NA
NA
1
NA
NA
1
3
-0.5645
0
2
NA
0
1
-0.4772
0
2
-0.9984
1
4
Just as the consequences of missingness vary by the type of variable that is missing, the imputation methods advocated to address missingness also vary. Importantly, these methods vary in the strength of the assumptions about missingness that are invoked to identify causal effects in the presence of missingness. We review three common approaches to imputation in #8-#10.
8 8. How do we address missingness of pre-treatment covariates and why does this matter?
As mentioned in #4, we should never “drop” observations on account of missing pre-treatment data. In order to estimate a model with covariate adjustment, thus, we need to “fill in” missing values to avoid dropping observations. We outline two forms of imputation advocated for missing pre-treatment covariates. The most common approach to address missingness of pre-treatment covariates is to create indicators for missingness and include these as covariates. To do this form of imputation:
Substitute a numerical value for the NA (as necessary). In the dataset below, we impute a 0 for all values of Xobs that are NAs. The new variable is named Ximputed.
Create an indicator for the missingness in each pretreatment variable. This indicator, Xmissing takes the value 1 whenever Xobs is NA, and a 1 otherwise.
Our imputed dataset is thus:
Xobs
Ximputed
Xmissing
Z
Yobs
-1.2070
-1.2070
0
0
3
NA
0.0000
1
0
2
1.0840
1.0840
0
1
3
-2.3460
-2.3460
0
1
4
0.4291
0.4291
0
1
2
0.5061
0.5061
0
0
NA
NA
0.0000
1
1
NA
NA
0.0000
1
1
3
-0.5645
-0.5645
0
0
2
NA
0.0000
1
0
1
-0.4772
-0.4772
0
0
2
-0.9984
-0.9984
0
1
4
Consider how this imputation changes the specification of a regression model. Instead of estimating:
Code
model1 <-lm(Yobs ~ Z + Xobs)
we estimate:
Code
model2 <-lm(Yobs ~ Z + Ximputed + Xmissing)
The estimator model2 does not drop observations on the basis of the missing pre-treatment variable Xobs like model1 does.
Alternatively, if pre-treatment missingness is minimal (less than 10% of observations), or when working with very small datasets with few observations relative to the number of covariates and missingness indicators, Lin, Green, and Coppock (2016) advocate imputing the (unconditional) mean of the observed pre-treatment covariate. Call this variable Ximputed_mean.
Xobs
Ximputed_mean
Z
Yobs
-1.2070
-1.2070000
0
3
NA
-0.4467375
0
2
1.0840
1.0840000
1
3
-2.3460
-2.3460000
1
4
0.4291
0.4291000
1
2
0.5061
0.5061000
0
NA
NA
-0.4467375
1
NA
NA
-0.4467375
1
3
-0.5645
-0.5645000
0
2
NA
-0.4467375
0
1
-0.4772
-0.4772000
0
2
-0.9984
-0.9984000
1
4
If we are simply imputing the pretreatment mean, then instead of estimating model1 (as above) our regression model should be:
Code
model3 <-lm(Yobs ~ Z + Ximputed_mean)
Since we have imputed missing values in Xobs when constructing Ximputed_mean, we will not lose observations on the basis of the missing pretreatment covariate when estimating model3.
9 9. We can bound ATEs to account for missing outcome data without making assumptions about the distribution of missing outcomes.
If we know the maximum and minimum values of the outcome variable, we can construct bounds on the ATE even in the presence of missing values of the dependent variable. For example, the range of the variable Yobs is 1 to 4. While we do not know what values missing values of Yobs would have been, we can take advantage of the fact that we know the maximum and minimum possible value to construct bounds on the ATE. This allows us to construct an interval estimate of the ATE instead of the point estimate we would construct if we had no missing data. These bounds are known as “extreme value bounds” or “Manski bounds” and do not invoke any additional assumptions about the value of Yobs.
Manski bounds consist of a maximum and minimum bound (estimate) of the possible ATE. To create these bounds, we impute the maximum or minimum value of the outcome variable. as a function of treatment assignment. Thus we construct:
A maximum bound by imputing the maximum value of the outcome for missing values in treatment (\(Z=1\)) and imputing the minimum value of the outcome for missing values in control (\(Z=0\)).
A minimum bound by imputing the minimum value of the outcome for missing values in treatment (\(Z=1\)) and imputing the maximum value of the outcome for missing values in control (\(Z=0\)).
Using the above dataset, we can construct two variables Y_maxbound and Y_minbound as follows:
Xobs
Z
Yobs
Y_maxbound
Y_minbound
-1.2070
0
3
3
3
NA
0
2
2
2
1.0840
1
3
3
3
-2.3460
1
4
4
4
0.4291
1
2
2
2
0.5061
0
NA
1
4
NA
1
NA
4
1
NA
1
3
3
3
-0.5645
0
2
2
2
NA
0
1
1
1
-0.4772
0
2
2
2
-0.9984
1
4
4
4
Without covariate adjustment, we can obtain our interval estimate of the ATE by estimating:
Our interval estimate of the ATE using Manski bounds is thus [0.5, 1.5].
An alternative approach to getting Manski bounds is to use the attrition package:
Code
library(attrition)R <-abs(1- missing)boundData <-as.data.frame(cbind(Yobs, Z, R))estimator_ev(Y = Yobs, Z = Z, R = R, minY =min(Yobs, na.rm = T), maxY =max(Yobs, na.rm = T), data = boundData)[c(3,4)]
low_est upp_est
0.5 1.5
As Manski bounds provide a highly conservative estimate of the ATE, one might want to use trimming bounds (also known as Lee bounds), which give bounds on the ATE for always reporters. Trimming bounds add the assumption of monotonic attrition \((r_i(1) \geq r_i(0) \text{ or } r_i(1) \leq r_i(0))\), getting rid of if treated reporters or if untreated reporters. Using the attrition package, we can get Lee bounds using the estimator_trim function:
Code
estimator_trim(Y = Yobs, Z = Z, R = R, data = boundData)[c(2,1)]
lower_bound upper_bound
1.0 1.2
10 10. Multiple imputation for missing outcomes allows for point estimation of ATEs, but relies on stronger assumptions than bounding.
The methods in #8 and #9 describe methods of single imputation, where a single value is substituted for missing values. In multiple imputation, we impute missing values of the dataset multiple times according to an assumed stochastic data generating process. Different methods for multiple imputation impose different structures and assumptions about the probability distributions governing the data generating processes used to impute missing values. In general, multiple imputation proceeds via three stages:
Imputation: Missing values are imputed via a random draw of plausible values under the specified data generating process. This creates a full dataset without missing values. Typically, researchers will impute at least five complete datasets. The only differences across these imputed datasets are the values that were missing in the original data.
Estimation: Estimate the ATE (or other estimand of interest) using each imputed dataset. This generates as many estimates and standard errors as there are imputed datasets.
Pooling estimates: Finally, researchers combine estimates from the different imputed datasets to generate a point estimate of the ATE and its stanard error. Typically, this point estimate can be calculated using rules laid out by Rubin (2004).
Multiple imputation is implemented in many software packages and relatively straightforward to implement. However, the specification of a data generating process from which datasets are imputed relies on additional assumptions about the correctness of the model of missingness (the data generating process). These assumptions are generally untestable and stronger than the standard experimental assumptions invoked to identify an interval estimate of the ATE using Manski bounds.